Keyword Extraction
May 16, 2017
문서에서 키워드 추출하기
memento 서비스에서 기술적으로 중요한 부분은 뉴스 기사의 키워드를 잘 추출해 내는 것 입니다. 이렇게 추출된 키워드를 저희는 문서의 기본적인 정수(essence)라고 생각하여 문서를 분류하고 정규화 합니다.
따라서 문서에서 키워드를 추출하고 분류하는 일은 어떠한 작업보다 기저에서 중요한 역할을 하는 작업으로 완성도와 품질에 직접적 영향을 끼치는 요인으로 많은 노력과 정성을 들여 어떤 키워드가 문서를 대표할까?, 어떻게 일반적인 키워드와 특별한 키워드를 구별할까?, 특정 키워드에서 어떤 의미를 끌어낼 수 있을까? 같은 문제를 해결해야 했습니다.
우선 키워드를 추출하기위해서 형태소 분석을 활용하여 키워드를 형태소 단위로 나누어 분석하는 과정을 거쳤습니다.
형태소 분석
자연어 처리에 있어 가장 중요하다고 볼 수 있는 형태소 분석은 문자열을 형태소열로 바꾸어 의미적인 단위로 구분하는 것을 말합니다.
영문 자료는 형태소 분석이 어렵지 않고 사실 띄어쓰기 단위와 형태소 단위가 크게 다르지 않습니다. 하지만 한글은 영어에 비해 형태소 분석의 난이도가 매우 높습니다.
형태소 분석이 매우 중요한 요소이고 실제 서비스에 있어서 성능을 좌우할만한 커다란 부분임에는 틀림없지만, 이를 직접 개발하거나 구현하는 것은 ROI가 낮다고 판단하여 많은 선행 연구를 참조하고 공개된 오픈소스를 활용하여 이에 필요한 비용을 크게 줄였습니다.
memento 서비스는 konlpy를 기본으로 한국어 형태소 분석을 진행하고 있습니다.
 또한 여러 기법을 추가하여 형태소를 재 구성하여 의미적으로 더 정확한 분석이 되도록 향상시켰습니다.
또한 여러 기법을 추가하여 형태소를 재 구성하여 의미적으로 더 정확한 분석이 되도록 향상시켰습니다.
문장을 형태소로 분리한 후에 어떤 키워드가 중요한 키워드인지 알아내는 방법으로 일반적으로 텍스트 마이닝에서 사용하는 tf-idf(Term Frequency - Inverse Document Frequency) 로 문서의 키워드를 분류해 보았습니다. tf-idf는 여러 문서로 이루어진 문서군에서, 어떤 단어가 특정 문서 내에서 얼마나 중요한지 나타내는 통계적 수치입니다. 일반적으로 문서의 핵심어를 추출하거나, 검색 엔진의 결과 순위를 정하거나, 문서의 비슷한 정도를 구하는 용도로 사용됩니다.
TF-IDF
TF(term frequency)는 특정한 단어가 문서 내에서 얼마나 자주 등장하는지를 나타내는 값으로, 문서내에서 특정 단어가 많이 등장한다면 이 단어가 중요한 키워드일 수 있습니다. 하지만 이 단어가 다른 문서에서도 많이 등장하게 된다면 이는 단순히 흔한 단어일수도 있습니다. 이것은 DF(document frequency)라고 하는데, tf-idf란 이 값의 역수 IDF(inverse document frequency)를 TF에 곱한 것을 나타냅니다.
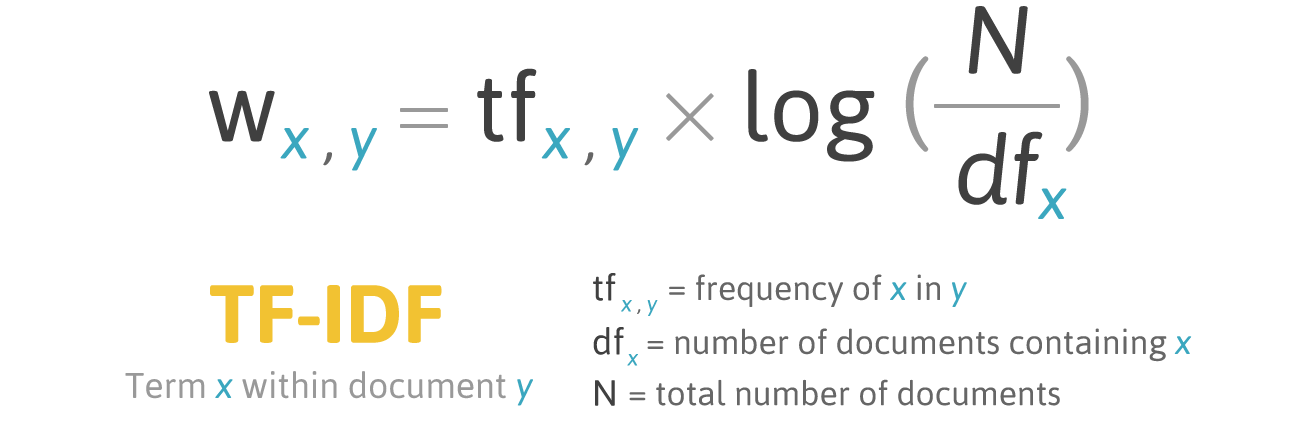
그러면 이 값이 어떤 의미가 있을까요? IDF값은 보통 문서군 성격에 의해 결정됩니다. 예를들어 ‘탄핵‘이라는 단어는 일반적인 문서에서는 자주 등장하지 않기 때문에 IDF값이 매우 높습니다. 하지만 ‘대통령 탄핵‘이라는 키워드로 뉴스를 검색했을 때 나오는 문서들 사이에서는 당연하게도, 탄핵 이라는 키워드를 통해 검색된 문서기 때문에, 이 문서군내에서는 IDF값이 낮아지게 됩니다.
memento 서비스에서는 이 방법을 사용하여 클러스터링의 정확도를 평가하고, 연관 인물을 추출하고 동명이인을 분리하는 기본적인 수단으로 사용합니다.
나아가 여러 연구를 학습하여 tf-idf를 문서 특성에 맞춰서 설계하였습니다. TF-IDF와 소설 텍스트의 구조를 이용한 주제어 추출 연구1에서는 소설의 특성을 활용해 소설을 머리말, 대화문, 비대화문, 맺음말의 4개의 구조로 분리한 후 tf-idf를 적용하여 성능 향상을 이끌어 내었고, TF-IDF를 이용한 키워드 추출 시스템 설계2에서는 Anchor Text를 활용하여 키워드 분류의 정확도를 향상시켰습니다.
여기에 착안하여 수집대상이 인터넷 뉴스의 특성을 이용하여 문서의 시작과 끝에 나타나는 불필요한 단락을 제거하고, 문서 구조에서 중요한 인용구를 중점으로 분석하여 더 나은 키워드를 추출할 수 있게 되었습니다. 또한, 키워드에 대한 단어 사전을 미리 만들어 해당 키워드가 우리가 원하는 의미의 키워드와 얼마나 비슷한지 먼저 측정하여, 동음이의어와 동명이인을 더 잘 구별해 내는 성능 향상을 이루어 내었습니다.
memento 서비스는 반 자동화로 매거진을 생성하기 때문에 초기에 설정된 인물들 외에 서비스가 지속되면서 수집된 뉴스를 기반으로 새로 수집할 엔티티들을 자동으로 추가해야 합니다. 이를 위해서는 무엇이 추가해야할 엔티티이고 무엇은 그렇지 않은지 구별하는 기술이 필요합니다. 이것을 보통 개체명 인식, NER(Named-entity recognition)이라고 하는데 memento 서비스에서는 어떻게 구현했는지 알아보겠습니다.
Named-entity recognition
먼저 형태소 분석기의 고유 명사를 개체명으로 여기는 방법도 매우 간단한 해결책 중 하나였습니다. 하지만 비교적 정확도가 낮고, 정확하진 않더라도 많은 후보군을 추출해야 하는 서비스 특성상 맞지 않는 방법이기에, 실제 개체명이 아닌 것 까지 추출하더라도, 개체명을 인식하지 못하는 경우가 적도록 좀 더 큰 의미의 개체명까지 추출하고자 하였습니다.
한국어 개체명 인식 및 분류3에서는 개체명 인식을 위한 자질이 영어에 비해 비교적 부족하다는 문제를 극복하기 위해 word embedding 자질을 개체명 인식을 위한 자질로 사용하는 방법으로 성능을 향상시켰음을 보여줍니다.
따라서 doc2vec으로 embedding 된 단어들을 클러스터링 하여 개체명을 인식시키는데에 활용하였습니다. 또한 공개된 풍부한 영문 NLP 패키지들4을 활용하고 한글 형태소에 맞게 변형하여 앙상블하였습니다.
정확하게 개체명만을 분리하진 않지만 개체명이라고 생각될 만한 단어들을 모두 분류해 내어 후보군으로 만들었습니다. 이렇게 분류된 개체명 후보군은 필요한 만큼의 정보가 쌓이면 실제 publishing 될 엔티티로 등록되게 됩니다.
물론 품질의 검수를 위해 이러한 과정은 사람이 확인하고 등록하게 되도록 만들어 두었습니다. 궁극적인 목표는 완전한 자동화 이겠지만, 사람이 즐거운 컨텐츠는 아직까진 아무래도 사람이 가장 잘 만들어 낼 테니까요.
더 나은 서비스를 위해
물론 여기에 설명된 것 외에도 많은 노력과 연구의 산물이 서비스에 녹아 있습니다. 하지만 더 나은 서비스를 위해 여러 선행 연구와 공개된 오픈소스들을 계속 참고하고 있습니다. 그리고 많은 데이터를 수집하여 더 나은 품질 향상에 기여할 수 있도록 스스로 정확도를 높이는 시스템을 설계하기 위해 최선을 다하고 있습니다.
예를 들어 후보군으로 추출된 개체명에서 사람이 필요한 개체명이라고 판단하는 패턴을 통해 궁극적으로 자동화된 신규 개체명 등록을 위해 노력하고 있고, 미리 정의된 단어 사전의 품질을 높이기 위해 누적되는 데이터에서 새로 가중치를 업데이트 하고 있습니다.
-
Eun-Soon You et al. “Study on Extraction of Keywords Using TF-IDF and Text Structure of Novels” Journal of The Korea Society of Computer and Information, February 2015 ↩
-
Mal-Rey Lee et al, “Design of Keyword Extraction System Using TF-IDF”, Korean Journal of Cognitive Science, March 2002 ↩
-
Yunsu Choi et al, “Korean Named Entity Recognition and Classification using Word Embedding Features”, The Korean Institute of Information Scientists and Engineers, June 2016 ↩